
データ提供 PR TIMES
本記事の内容に関するお問い合わせ、または掲載についてのお問い合わせは株式会社 PR TIMES (release_fujitv@prtimes.co.jp)までご連絡ください。また、製品・サービスなどに関するお問い合わせに関しましては、それぞれの発表企業・団体にご連絡ください。
プレスリリース配信元:株式会社ELYZA
日本語理解や対話品質を評価するベンチマークにおいて高い性能を実現

大規模言語モデル(以下、LLM)の研究開発と社会実装を進める株式会社ELYZA(代表取締役:曽根岡侑也、以下当社)は、KDDI株式会社のGPU基盤を利用して、日本語における知識・指示追従能力を強化した拡散大規模言語モデル(以下、dLLM)である「ELYZA-LLM-Diffusion」シリーズを開発し、商用利用可能な形で公開しました。本モデルの公開に併せて、デモも公開しております。ぜひお試しください。
拡散型大規模言語モデルとは
拡散大規模言語モデル(Diffusion Large Language Model、略称: dLLM)とは、元来は画像生成AIを中心に活用されていた手法である拡散モデルを、言語生成に活用したものです。従来の逐次的なテキスト生成モデルである自己回帰モデル(Autoregressive Model、略称:ARモデル)とは異なり、段階的にノイズを除去してテキストを生成する新しいタイプのAIモデルです。 dLLMは、元のデータにノイズを加えていきノイズだけのデータに変換する拡散過程をおこない、そこからノイズを取り除く逆拡散過程を学習させることで、綺麗なデータをノイズから生成することができます。この生成方法の利点として、dLLMはARモデルのように文章を左から右へと逐次的に生成する必要がないため、設計次第ではより少ない処理回数で生成を行うことが可能です。その結果、推論をより効率化でき、生成速度の向上や消費電力の低減が期待されます。
一方で、dLLMは学習コストの高さや性能面の課題に加え、推論基盤等のエコシステムが成熟途上であることから、現時点での実利用は限定的です。しかし、基礎研究は着実に進展しており、将来的に実用化が進む可能性のある技術として注目されています。また、オープンなモデルも徐々に登場し始めていますが、その多くは英語データを中心に学習されたものとなっています。
開発したモデルについて
今回当社では、HKU NLP Groupが開発・公開しているdLLMである「Dream-org/Dream-v0-Instruct-7B」をベースに、日本語データによる追加事前学習および指示学習を行うことで、日本語の知識力や指示追従能力を向上させた「ELYZA-LLM-Diffusion」シリーズを開発しました。現在公開しているモデルは以下になります。■ELYZA-Diffusion-Base-1.0-Dream-7B
「Dream-v0-Instruct-7B」に日本語データの追加事前学習を行ったモデルです。
https://huggingface.co/elyza/ELYZA-Diffusion-Base-1.0-Dream-7B
■ELYZA-Diffusion-Instruct-1.0-Dream-7B
「ELYZA-Diffusion-Base-1.0-Dream-7B」に指示学習を行ったモデルです。
https://huggingface.co/elyza/ELYZA-Diffusion-Instruct-1.0-Dream-7B
dLLMとARモデルにおける実際の生成のプロセスの違いについて、以下の動画でご確認ください。

また、本モデルを用いたchatUI形式のデモもHugging Face hub上で公開しております。
https://huggingface.co/spaces/elyza/ELYZA-Diffusion-Instruct-Dream-7B-Demo
※アクセス過多によりリクエストが処理されるまで待ち時間が発生することがあります。
モデルの開発プロセスや技術的な詳細、各種ベンチマークの解説を含む評価の詳細情報については公式テックブログにて解説しています。
https://zenn.dev/elyza/articles/f9dd010e895a34
本モデルの性能について
本モデルが日本語タスクにおいてどのような性能を示すのかを確認するため、日本語タスクを中心に評価を行いました。比較対象として、dLLMおよびARモデルを用いています。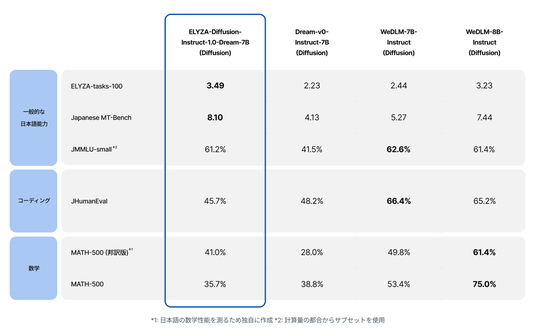
評価の結果、一般的な日本語能力が問われるタスクにおいては、ELYZA-Diffusion-Instruct-1.0-Dream-7B が、既存のオープンなdLLMと比較しても同等かより優れた性能を発揮しています。
本研究の狙い
AI活用による電力消費量が増加する中、発電量の不足、それに伴うAI用データセンターの不足が現在国際的な社会問題となっています。そのため、今後生成AIの活用を進めていくにあたり、LLMをはじめとする基盤モデルの効率的な推論と学習が必要になってきます。本研究対象であるdLLMは、少ない処理回数で文章を生成する特徴を持っているため、ARモデルと比較して生成に必要な時間が短く、電力消費も抑えられる可能性があります。
本研究をさらに進めることで、電力効率の良い高性能な日本語LLM開発をさらに加速させることが期待できます。
当社は今後もLLMを中心とした最先端の研究開発に取り組んでいくとともに、その研究成果を可能な限り公開・提供することを通じて、国内におけるLLMの社会実装の推進、並びに自然言語処理技術の発展を支援してまいります。
ELYZA会社概要
株式会社ELYZAは、「未踏の領域で、あたりまえを創る」という理念のもと、日本語の大規模言語モデルに焦点を当て、企業との共同研究やクラウドサービスの開発を行なっております。先端技術の研究開発とコンサルティングによって、企業成長に貢献する形で大規模言語モデルの導入実装を推進します。<会社概要>
社名 :株式会社ELYZA
所在地 :〒113-0033 東京都文京区本郷3-15-9 SWTビル 6F
代表者 :代表取締役 曽根岡侑也
設立 :2018年9月
URL :https://elyza.ai/
企業プレスリリース詳細へ
PR TIMESトップへ




